大数据框架发展史 - 4代大数据的计算引擎
来源:科象教育

如今的我们正生活在新一次的信息革命浪潮中,5G、物联网、智慧城市、工业4.0、新基建……等新名词层出不穷,唯一不变的就是变化!对于我们所学习的大数据分析来说更是这样:数据产生的越来越快、数据量越来越大,数据的来源越来越千变万化,数据中隐藏的价值规律更是越来越被重视!数字化时代的未来正在被我们创造!。


这几年大数据的飞速发展,出现了很多热门的开源社区,其中著名的有 Hadoop、Storm,以及后来的 Spark,他们都有着各自专注的应用场景。Spark 掀开了内存计算的先河,也以内存为赌注,赢得了内存计算的飞速发展。Spark 的火热或多或少的掩盖了其他分布式计算的系统身影。就像 Flink,也就在这个时候默默的发展着。
在国外一些社区,有很多人将大数据的计算引擎分成了 4 代,当然,也有很多人不会认同。我们先姑且这么认为和讨论。
首先第一代的计算引擎,无疑就是 Hadoop 承载的 MapReduce。它将计算分为两个阶段,分别为 Map 和 Reduce。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个 Job 的串联,以完成一个完整的算法,例如迭代计算。
-
批处理
-
Mapper、Reducer
由于这样的弊端,催生了支持 DAG 框架的产生。因此,支持 DAG 的框架被划分为第二代计算引擎。如 Tez 以及更上层的 Oozie。这里我们不去细究各种 DAG 实现之间的区别,不过对于当时的 Tez 和 Oozie 来说,大多还是批处理的任务。
-
批处理
-
1个Tez = MR(1) + MR(2) + ... + MR(n)
-
相比MR效率有所提升
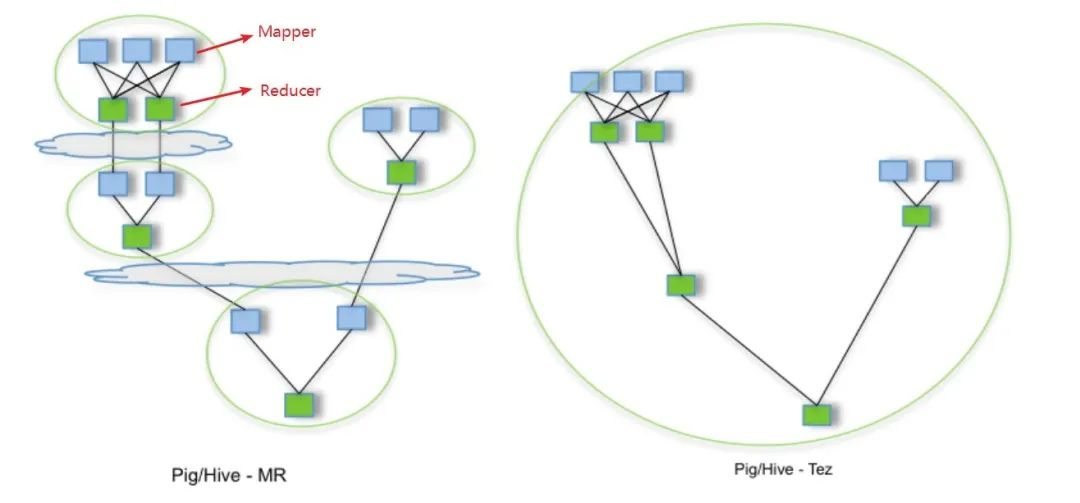
接下来就是以 Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及强调的实时计算。在这里,很多人也会认为第三代计算引擎也能够很好的运行批处理的 Job。
-
批处理、流处理、SQL高层API支持
-
自带DAG
-
内存迭代计算、性能较之前大幅提升
随着第三代计算引擎的出现,促进了上层应用快速发展,例如各种迭代计算的性能以及对流计算和 SQL 等的支持。Flink 的诞生就被归在了第四代。这应该主要表现在 Flink 对流计算的支持,以及更一步的实时性上面。当然 Flink 也可以支持 Batch 的任务,以及 DAG 的运算。
-
批处理、流处理、SQL高层API支持
-
自带DAG
-
流式计算性能更高、可靠性更高
历史的发展从来不会一帆风顺,随着大数据时代的发展,海量数据和多种业务的实时处理需求激增,比如:实时监控报警系统、实时风控系统、实时推荐系统等,传统的批处理方式和早期的流式处理框架因其自身的局限性,难以在延迟性、吞吐量、容错能力,以及使用便捷性等方面满足业务日益苛刻的要求。在这种形势下,Flink 以其独特的天然流式计算特性和更为先进的架构设计,极大地改善了以前的流式处理框架所存在的问题。