数据分析学习之3W1H分析法,全面构建数据分析思维!
来源:科象教育
Why-What-How」在讲解概念和执行上是个不错的思维模型,本文依例按此框架来拆分「数据分析」。
相信很多朋友已经有了较丰富的分析经验,这里权且从个人的角度进行梳理,以资参考。为了帮助大家更好地理解本文,先贴出一张思维导图:
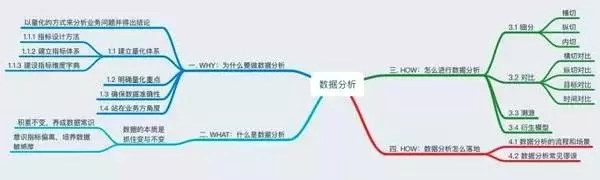
01 WHY:为什么要做数据分析
在目前讲解数据分析的文章里,大多数会忽略数据分析本身的目的。这会导致我们在执行时,会出现动作变形的情况。以终为始,才能保证不会跑偏。个人的理解上, 数据分析是为了能以量化的方式来分析业务问题并得出结论。其中有两个重点词语:量化和业务。
量化是为了统一认知,并且确保路径可回溯,可复制。 统一认知后,才能保证不同层级,不同部门的人在平等话语权和同一个方向进行讨论和协作,才能避免公司内的人以「我感觉」「我猜测」来猜测当前业务的情况。
除了「量化」之外,另外一个重点词语是「业务」。只有解决业务问题分析才能创造价值,价值包括个人价值和公司价值。对于公司来讲,你提高了收入水平或者降低了业务成本,对于个人来讲,你知道怎么去利用数据解决业务问题,这对个人的能力成长和职业生涯都有非常大的帮助。
如何站在业务方的角度思考问题呢,总结起来就是八个字「忧其所虑,给其所欲」主要是在这以下几个环节:
1. 沟通充分
2. 结论简明
3. 提供信息量及可落地建议
4. 寻求反馈
在沟通上,确定业务方想要分析什么,提出更合理专业的衡量和分析方式,同时做好节点同步,切忌一条路走到黑。在分析业务需求上,跟很多产品需求分析方法论是类似的,需要明确所要数据背后的含义。举例来讲,业务方说要看「页面停留时长」,但他实际想要的,可能是想衡量用户质量,那么「留存率」「目标转化率」才是更合适的指标。
在阐述分析结果上,要记得结论先行,逐层讲解,再提供论据。论据上,图 > 表 > 文字。因为业务方或管理层时间都是有限的,洋洋洒洒一大篇邮件,未看先晕,谁都没心思看你到底分析了啥。需要做到,在邮件最前面,用 1-3 句话先把结论给出来,即使需求方不看后续内容都可以了解你报告 80% 的内容。
在「提供信息量及可落地建议」上,先要明白什么叫信息量:提供了对方不知道的信息。太阳明天从东方升起不算信息量,从西方升起才是。在分析的过程中,一定要从专业的角度,从已知边界向未知边界进军,力求角度新颖论证扎实,并且根据分析内容给出可落地的建议。
02 WHAT:什么是数据分析
数据分析的本质是抓住「变」与「不变」。「变」是数据分析的基础,如果一个业务每天订单是 10000 单,或者每天都是以 10% 的速度稳步增长,那就没有分析的必要了。而若想抓住「变」,得先形成「不变」的意识。
积累「不变」,就是养成「数据常识(Data Common Sense)」的过程。「不变」是根据对历史数据不断的观察和积累而来。一般来说会是个范围,范围越精准,你对「变」就越敏感。这里有三个个人的习惯,可以帮助养成「不变」:
形成习惯,每天上班第一时间查看数据:实时&日周月报;记住各个指标大数,反复推算,记录关键数据(榜单&报告)
大部分指标没有记住全部数字的必要,简单记住大数,万以下只需要记到万位,有些数字只需要记住百分比。 而指标之间的推算可以帮助你对各个指标的数量级关系和逻辑脉络梳理清楚,出现波动时便能更加敏感。记录关键数据是将工作生活遇到的比较有趣的榜单或数据报告保存在一个统一的地方,方便查阅和分析。
在「不变」的基础上,便能逐渐培养出指标敏感性,即意识指标偏离的能力。这主要是通过各种日环比,周月同比的监控以及日常的好奇心来保持。我们从一个 Questmobile 榜单上,来简单看下「指标偏离」是怎么应用到日常的分析上的:
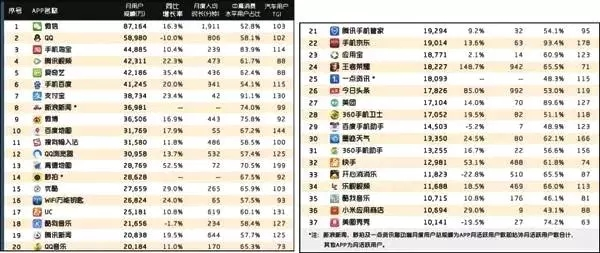
这里先跟大家分享下怎么看这种榜单:
1. 看整体排行:看哪些 APP 排在前方是出乎你意料之外的
2. 分行业看排行:看行业里排行及其变动
3. 看增长率:哪些 APP 增长比较快
4. 看使用时长等其他指标
数据分析的定义,还有国外一本商务分析的书籍的定义作为注脚

03 HOW:怎么进行数据分析
任何数据分析都是「细分,对比,溯源」这三种行为的不断交叉。最常见的细分对比维度是时间,我们通过时间进行周月同比,发现数据异常后,再进行维度或流程上的细分,一步步拆解找到问题所在。
如果找到了某个维度的问题,则需要溯源到业务端或现实端,确认问题产生的源头。如果多次细分对比下来仍然没有确认问题,则需要溯源到业务日志或用户访谈来更进一步摸清楚情况。
3.1 细分
在细分方式上,主要有以下三种方式
1. 横切:根据某个维度对指标进行切分及交叉分析
2. 纵切:以时间变化为轴,切分指标上下游
3. 内切:根据某个模型从目标内部进行划分
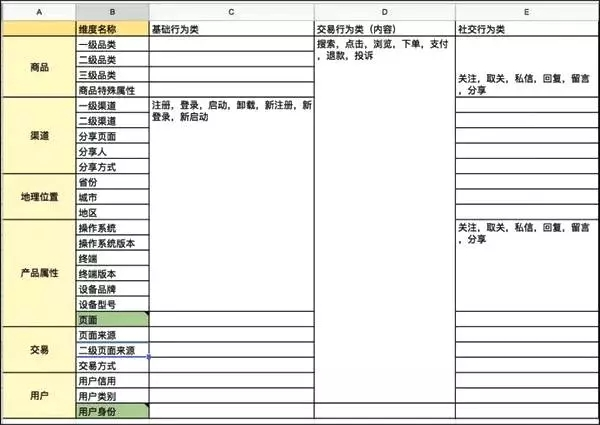
横切上,我们对维度和指标做做了分类和交叉,当某一类的指标出现问题时,我们便知道该从什么维度进行分析。在进行横切分析时,经常需要多个维度交叉着使用。这在数据分析术语上叫:交叉多维分析。这也是刚才讲的「维度总线矩
阵」看到的各维度交叉情况了。
纵切上,有目的有路径,则用漏斗分析。无目的有路径,则用轨迹分析。无目的无路径,则用日志分析。
漏斗分析分为长漏斗和短漏斗。长漏斗的特征是涉及环节较多,时间周期较长。常用的长漏斗有渠道归因模型,AARRR,用户生命周期漏斗等等。短漏斗是有明确的目的,时间短,如订单转化漏斗和注册漏斗。在轨迹分析里,桑基图是一种常用的方式。常见于各页面的流转关系,电商中各品类的转移关系等等。日志分析,则通过直接浏览用户前后端日志,来分析用户的每一个动作。
各种手段的细分往往交叉着使用,如订单漏斗纵切完可以接着横切,看看是哪个维度的转化率导致的问题。
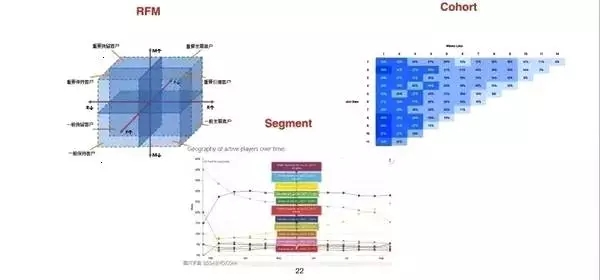
内切上,主要是根据现有市面上常见的分析模型,RFM,Cohort 和 Segment等方式进行分析。RFM 即最近购买时间,频率及金额三个指标综合来判定用户忠诚度及粘性。Cohort,即同期群分析,是通过对不同时期进入平台的新用户分群分析,来区分不同新用户的质量,如留存率或目标转化率等。Segment 通过若干个条件对用户分层,然后针对不同用户进行分层分析和运营,如用户活跃度分层等等。
3.2 对比
对比主要分为以下几种:
1. 横切对比:根据细分中的横切维度进行对比,如城市和品类
2. 纵切对比:与细分中的纵切维护进行对比,如漏斗不同阶段的转化率
3. 目标对比:常见于目标管理,如完成率等
4. 时间对比:日环比,周月同比;7天滑动平均值对比,7天内极值对比
时间对比严格来说属于横切对比。但因为时间这个维度在数据分析和产品中极为重要,所以单拎出来说。横切对比中,有个比较著名的数据应用方式即是「「排行榜」。通过这种简单粗暴的方式,来驱动人们完成目标,或者占领人们的认知。前者有销售完成排行榜。后者有品类售卖畅销榜。
3.3 溯源
经过反复的细分对比后,基本可以确认问题所在了。这时候就需要和业务方确认是否因为某些业务动作导致的数据异常,包括新版本上线,或者活动策略优化等等。
如果仍然没有头绪,那么只能从最细颗粒度查起了,如用户日志分析、用户访谈、外在环境了解,如外部活动,政策经济条件变化等等
3.4 衍生模型
在「细分对比」的基础上,可以衍生出来很多模型。这些模型的意义是能够帮你快速判断一个事情的关键要素,并做到不重不漏。这里列举几个以供参考:
1. Why-How-What
2. 5W1H
3. 5Why
4. 4P模型(产品,价格,渠道,宣传)
5. SWOT 模型(优势,劣势,机会,威胁)
6. PEST 模型(政治,经济,社会,科技)
7. 波士顿矩阵
而当你在竞品做比对分析时,SWOT 或者 4P 模型能够给你提供不同的角度。
04 数据分析如何落地
以上讲的都偏「道术技」中的「术」部分,下面则通过汇总以上内容,和实际工作进行结合,落地成「技」部分。
4.1 数据分析流程和场景
根据不同的流程和场景,会有些不同的注意点和「术」的结合
4.2 数据分析常见谬误
控制变量谬误:在做 A/B 测试时没有控制好变量,导致测试结果不能反映实验结果。或者在进行数据对比时,两个指标没有可比性。
样本谬误:在做抽样分析时,选取的样本不够随机或不够有代表性。举例来讲,互联网圈的人会发现身边的人几乎不用「今日头条」,为什么这 APP 还能有这么大浏览量?有个类似的概念,叫幸存者偏差。
定义谬误:在看某些报告或者公开数据时,经常会有人鱼目混珠。「网站访问量过亿」,是指的访问用户数还是访问页面数?
比率谬误:比率型或比例型的指标出现的谬误以至于可以单独拎出来将。一个是每次谈论此类型指标时,都需要明确分子和分母是什么。另一方面,在讨论变化的百分比时,需要注意到基数是多少。有些人即使工资只涨 10% ,那也可能是 150万…
因果相关谬误:会误把相关当因果,忽略中介变量。比如,有人发现雪糕的销量和河溪溺死的儿童数量呈明显相关,就下令削减雪糕销量。其实可能只是因为这两者都是发生在天气炎热的夏天。天气炎热,购买雪糕的人就越多,而去河里游泳的人也显著增多。
辛普森悖论:简单来说,就是在两个相差较多的分组数据相加时,在分组比较中都占优势的一方,会在总评中反而是失势的一方。